You can now subscribe to get notified of my latest posts!
This post is the third post in a series of posts I have written as part of a data analytics pipeline spanning multiple languages, databases, and environments. You can find more about the pipeline in my final post here.
I am currently working on a different project which consists of me building a data pipeline to stitch together different technologies/languages. One part of the pipeline consists of consuming data from PubSub+ queue and writing it to Google’s fully managed, data warehouse solution, BigQuery.
If you have been involved with cloud computing recently, you would recognize BigQuery. It is one of the most popular data warehouse solutions out there currently and a strong competitor to AWS’s Redshift.
And with many organizations slowly moving their on-prem applications/systems to serverless, managed services on the cloud, there is a need to easily migrate data from on-prem to the cloud in a secure and cost-effective manner. Solace’s PubSub+ event broker allows you to do that easily.
Your on-prem applications can publish data to a local instance of PubSub+ which can be easily connected to a PubSub+ broker running locally on Google Cloud Platform (GCP) and connected via Event Mesh. Once your applications are live on GCP, they can connect to the PubSub+ instance deployed locally on GCP and subscribe to messages being published by your on-prem applications. Once the subscriptions are established, your on-prem messages will be dynamically routed to GCP.
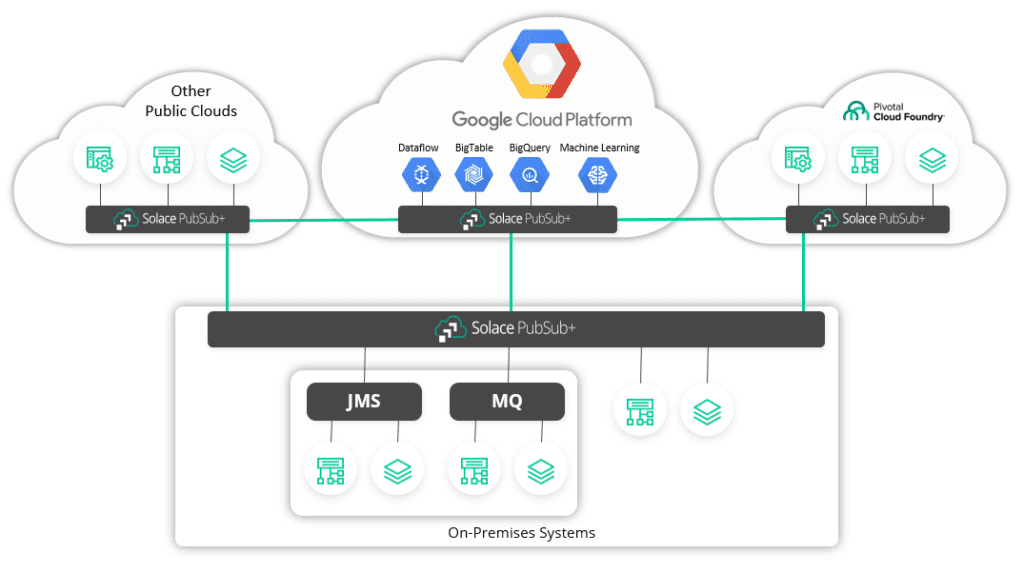
Additionally, you can use PubSub+’s rich hierarchical topics and powerful wildcard filtering, to only migrate messages belonging to specific topics to GCP. This saves you networking costs and provides additional security.
In this post, I will show you how you can generate a simple streaming pipeline that consumes messages from a PubSub+ queue and writes them to BigQuery using a popular open-source tool, Apache Beam.
What is Apache Beam?
“Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Apex, Apache Flink, Apache Spark, and Google Cloud Dataflow.” – Apache Beam Overview
Apache Beam is pretty much the de-facto tool for integrating with GCP services such as BigTable, BigQuery, pub/sub etc. Google also provides “a fully managed service for executing Apache Beam pipelines within the Google Cloud Platform ecosystem” called Google Dataflow.
Architecture
Before we get into the details, let’s take a look at what our high-level architecture looks like:
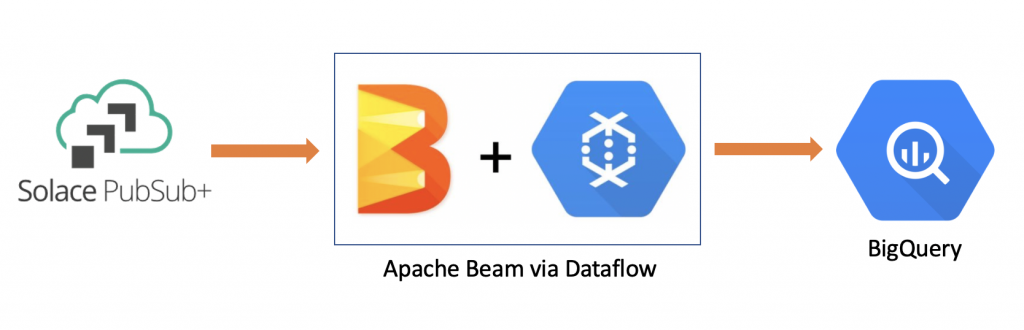
We will have a queue in PubSub+ which is subscribed to some topics and hence, will attract any messages that are published to those topics. Whenever a message is enqueued in our queue, our Apache Beam pipeline, deployed on Dataflow, will consume that message, transform it appropriately, and then write it to BigQuery.
Solace-Beam I/O connector
We will be using the Solace-Beam I/O connector provided by Solace to consume data from PubSub+ (github). The repo provides some useful examples in solace-apache-beam-samples directory which you can use to build your own custom pipelines. The pipeline that I have built is based on SolaceRecordTest.java code.
PubSub+ –> Beam/Dataflow –> BigQuery pipline
You can find the pipeline I have built here.
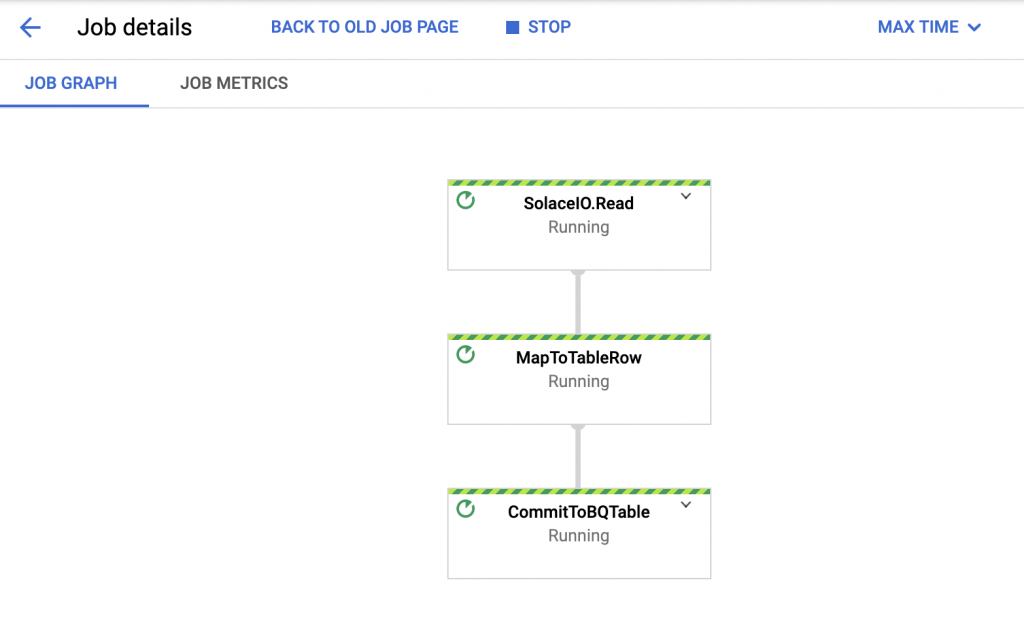
The pipeline consists of three different operations:
- SolaceIO – reading data from a PubSub+ queue
- MapToTableRow – transformation step which formats the payload and converts it to a BigQuery row
- CommitToBQTable – final step which commits rows to BigQuery
My initial payload looks like this:
[{"date":"2020-06-07","sym":"DUMMY","time":"22:58","lowAskSize":20,"highAskSize":790,"lowBidPrice":43.13057,"highBidPrice":44.95833,"lowBidSize":60,"highBidSize":770,"lowTradePrice":43.51274,"highTradePrice":45.41246,"lowTradeSize":0,"highTradeSize":480,"lowAskPrice":43.67592,"highAskPrice":45.86658,"vwap":238.0331}]In the second part of the pipeline (MapToTableRow), I take this payload and clean it by removing the quotes, brackets and braces so that it looks like this:
date:2020-06-07,sym:DUMMY,time:22:58,lowAskSize:20,highAskSize:790,lowBidPrice:43.13057,highBidPrice:44.95833,lowBidSize:60,highBidSize:770,lowTradePrice:43.51274,highTradePrice:45.41246,lowTradeSize:0,highTradeSize:480,lowAskPrice:43.67592,highAskPrice:45.86658,vwap:238.0331Then, I take this blob and put it into a HashMap using a for-loop.
// Clean up the payload so we can easily map the values into a HashMap
String[] pairs = c.element().getPayload().replace("[", "")
.replace("]", "")
.replace("{", "")
.replace("}", "")
.replace("\"", "").split(",");
for (int i=0;i<pairs.length;i++) {
String pair = pairs[i];
String[] keyValue = pair.split(":");
parsedMap.put(keyValue[0], keyValue[1]);
}Once I have my payload transformed into a HashMap, I generate a BigQuery row with the appropriate columns and data types.
TableRow row = new TableRow();
row.set("date", parsedMap.get("date"));
row.set("sym", parsedMap.get("sym"));
row.set("time", parsedMap.get("time"));
row.set("lowAskSize",Integer.parseInt(parsedMap.get("lowAskSize")));
....Finally, in the last step of the pipeline, I commit the row into BigQuery by specifying which table to use (tableSpec), which schema to use (tableSchema), whether to create the table or not (CREATE_IF_NEEDED), and whether to append new rows or replace existing ones (WRITE_APPEND):
.apply("CommitToBQTable", BigQueryIO.writeTableRows()
.to(tableSpec)
.withSchema(tableSchema)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND));tableSpec was defined earlier in the code by providing details about your GCP project, dataset, and table:
TableReference tableSpec =
new TableReference()
.setProjectId(options.getBigQueryProject())
.setDatasetId(options.getBigQueryDataset())
.setTableId(options.getBigQueryTable());
Creating BigQuery table
Now that our pipeline is ready, we need to create our BigQuery table with the appropriate corresponding schema to avoid any type mismatch.
You can create the table from BigQuery UI where you will be asked to provide a schema. Here is the schema I used for my usecase:
[
{
"name": "date",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "sym",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "time",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "lowAskSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "highAskSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "lowBidPrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "highBidPrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "lowBidSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "highBidSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "lowTradePrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "highTradePrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "lowTradeSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "highTradeSize",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "lowAskPrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "highAskPrice",
"type": "FLOAT",
"mode": "NULLABLE"
},
{
"name": "vwap",
"type": "FLOAT",
"mode": "NULLABLE"
}
]Once you have created the table, you are ready to run your Beam pipeline on Dataflow.
Executing Beam pipeline on Dataflow
To run the Dataflow pipeline from your workstation, you need to download Google Cloud SDK and then authenticate yourself. Here is a good YouTube video on how to do that.
To install it on my Mac, I ran these commands and followed the instructions on the terminal:
curl https://sdk.cloud.google.com | bashgcloud auth login
Once I have authenticated myself, I am ready to run Beam pipeline on Dataflow.
To run the SolaceBigQuery.java example, execute this command by providing appropriate arguments:
mvn compile exec:java -Dexec.mainClass=com.solace.connector.beam.examples.SolaceBeamBigQuery -Dexec.args="--bigQueryProject=<project> --bigQueryDataset=<dataset> --bigQueryTable=<table> --sql=<queue_name> --cip=<pubsub_host_port> --cu=<username> --cp=<password> --vpn=<pubsub_vpn_name> --project=<project_name> --tempLocation=gs://<bucket_name>/demo --workerMachineType=n1-standard-2 --runner=DataflowRunner --autoscalingAlgorithm=THROUGHPUT_BASED --maxNumWorkers=4 --stagingLocation=gs://<bucket_name>/staging" -Pdataflow-runnerNote: You will need to create a storage bucket in Google Storage for your temporary/staging files.
Once you have successfully executed the pipeline, go to Dataflow and you should see your new pipeline running with the three components discussed earlier:
You can then go to PubSub+’s Try Me! app and publish a message which will be enqueued in our queue. I will publish my message to topic: EQ/stats/v1/DUMMY which is mapped to my queue, demo.
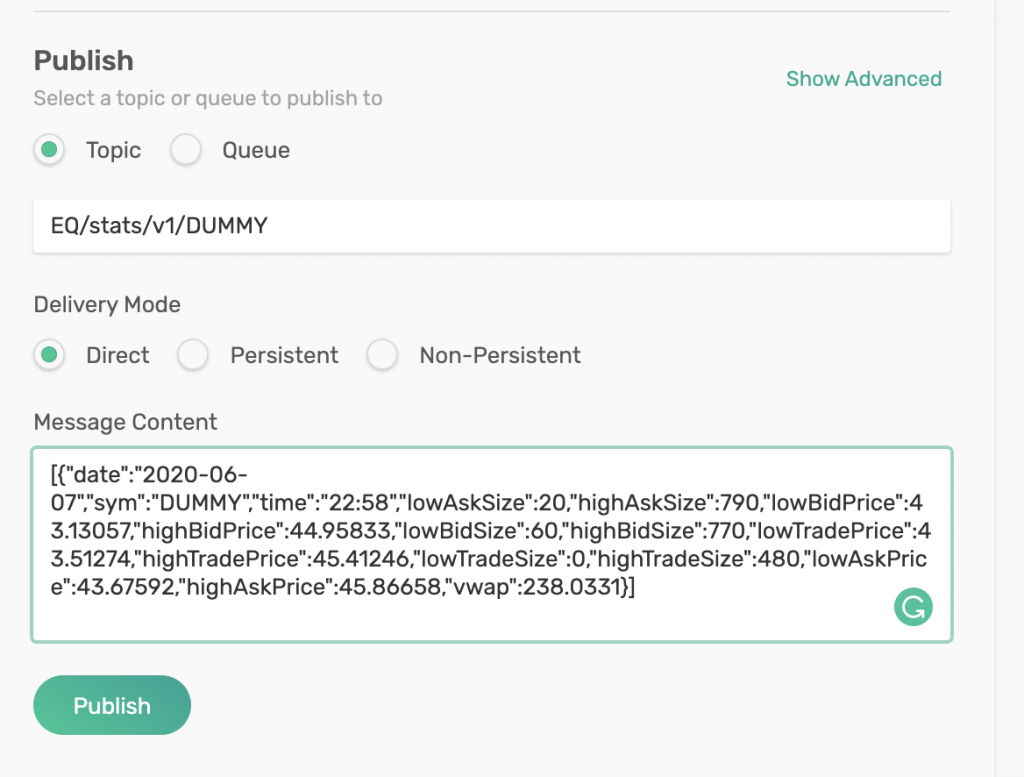
As soon as I click on Publish, my message will be sent and it will be enqueued in my demo queue. Then, soon, it will be consumed by my SolaceIO component in my Beam pipeline and written to BigQuery.
We can confirm that our pipeline is working by querying BigQuery:
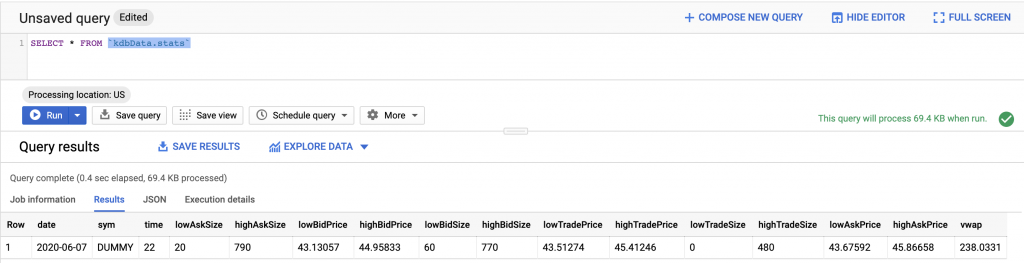
Wrap Up
That’s it for this demo! As you saw, it’s very easy to consume data from PubSub+ using Apache Beam and then write it to BigQuery. With a pipeline like this, you can easily migrate your data from on-prem applications to serverless, managed services on the cloud. Once the data is in BigQuery, you can do additional analytics and generate visualizations in GCP!